One research fabric, many machines — how our compute scales
Research progress is bounded by how many experiments you can run, read, and act on. So beyond the science, we've been quietly building the distributed compute fabric that AIOS runs on — and it's designed so the same architecture that coordinates a few machines today coordinates a fleet tomorrow.
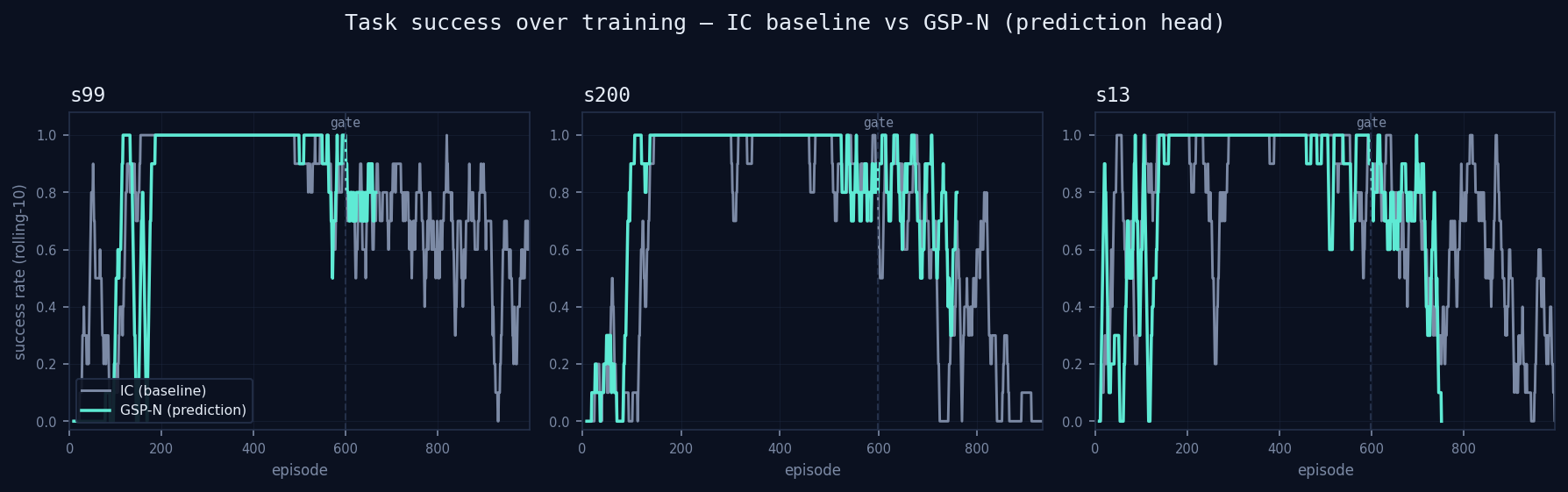
Today the fabric is three heterogeneous machines: a primary Linux training node with the most cores and cooling, and two Apple-silicon laptops that fill in around it. They are different operating systems, different chip architectures, different core counts — and the system treats them as one pool. As of this writing they've collectively run over 790,000 simulated transport episodes across nearly 3,000 training runs. The live counter on the front page is that number, read straight from the fabric.
The design is deliberately simple, because simple things scale:
- Every node is autonomous. Each runs its own dispatcher daemon and its own local registry of what has run and what is queued. There is no single point that has to be up for work to happen. A node that goes offline doesn't stall the others.
- Work is pinned, not guessed. An experiment batch declares which machine it belongs on, and it's submitted to that node. Each machine profiles itself — cores, memory, thermal headroom — and sets its own safe concurrency limit, so we never oversubscribe a laptop the way we'd load the Linux box.
- Code is kept in lockstep. A scheduled daily sync pulls every node to the same reviewed mainline, and a hard rule — no experiment launches from code that hasn't been merged and verified — means a result is always traceable to an exact, reviewed commit. Reproducibility isn't a cleanup step; it's a precondition to running at all.
Why build it this way for a company that's still pre-product? Because the shape of the problem doesn't change as it grows — only the scale does. Enrolling a new machine is the same operation whether it's a spare laptop or a rack of GPUs: install the daemon, let it profile itself, point batches at it. The heterogeneity we handle today — mixing an x86 Linux box with Apple-silicon laptops — is the same heterogeneity a growing team faces when it adds cloud instances, an on-prem cluster, and a dedicated training server. We're already running the multi-node case; scaling it is adding nodes, not rebuilding the system.
That's the enterprise story in one line: the research fabric is horizontal by construction. The same autonomous-node, self-profiling, pinned-work, reproducibility-first design that turns three personal machines into one research engine is the design that turns a hundred machines into one. And because AIOS is a thin shell over model-driven decisions, adding compute doesn't just mean more runs in parallel — it means the machine that plans, executes, and reads those runs gets more room to work. Compute and cognition scale together.
We built the fabric to remove our own bottleneck: the loop between an idea and the result that tells us whether it worked. Everything downstream — the science, the product — moves at the speed of that loop.